Computer System Architecture Review
一、导论
计算机系统结构3说法
- 五大部件:运算器、控制器、存储器、输入输出设备
- 软件和硬件组成
- 由人员、数据、设备、持续和规程组成
冯诺伊曼结构
特点:存储程序、运算器为中心、集中控制
①存储器是按地址访问的顺序线性编址的一维结构,每个单元的位数是固定的
②指令由操作码和地址码组成
③指令在存储器中是按其执行顺序存储的,由程序计数器指明每条指令所在单元的地址。
④在存储器中指令和数据被同等对待
⑤计算机系统结构以运算器、控制器为中心
⑥指令、数据均以二进制编码表示,采用二进制运算。
现代计算机对冯的改进:
- 不变:存储程序
- 改变:存储器为中心,总线结构,分散控制
计算机系统层次结构
- 虚拟计算机:由软件实现的机器。从不同角度所看到的计算机系统属性是不同的。
系统结构2种定义
从程序设计者所看到的计算机属性,即概念性结构和功能特性
研究软硬件功能分配和对软硬件界面的确定
计算机组成与实现
- 计算机组成:计算机系统结构的逻辑实现
- 计算机实现:计算机组成的物理实现
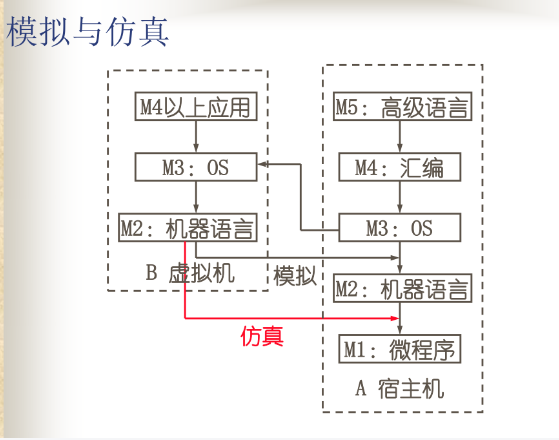
模拟和仿真
在某一系统结构上实现另一种系统结构
- 模拟:用机器语言程序解释实现程序移植的方法
- 仿真:微程序直接解释另一种机器的指令系统
加速比


计算机系统结构分类(Flynn分类)
- SISD:单指令流单数据流 -> 串行计算机
- SIMD:单指令流多数据流 -> 并行处理机
- MISD:多指令流单数据流 -> 无食用价值
- MIMD:多指令流多数据流 -> 多处理机和多计算机
- SPMD:单程序多数据流 -> MIMD的一个子类,基于Cluster
- SIMT:单指令多线程 -> Nvidia 公司提出,GPU
二、处理器
CISC & RISC
- 复杂指令系统CISC
- 提供复杂指令来提高性能
- 所含指令至少300条,甚至超过500条
- 设计目的:用最少的机器语言指令来完成所需的计算任务
- 使得硬件越来越复杂,造价相应提高,复杂的指令系统不但不容易实现,还可能降低性能
- 精简指令系统RISC
- 只保留使用频率很高的少量指令
- 其他复杂功能通过组合指令(子程序)实现
- 提供一些必要的指令以支持OS和高级语言
OpenMP
执行模型采用Fork-Join形式和共享内存模型
是任务级线程,不是SIMD
#pragma omp <directive>[clause [[,]clause]…]常用的功能指令如下:
parallel:用在一个结构块之前,表示这段代码将被多个线程并行执行。parallel for:parallel和for指令的结合,也用于for循环语句之前,表示for循环体的代码将被多个线程并行执行,同时具有并行域的产生和任务分配两个功能。reduction:执行指定的归约运算。single:用在并行域内,表示一段只被单个线程执行的代码。critical:用在一段代码临界区之前,保证每次只有一个OpenMP线程进入。barrier:用于并行域内代码的线程同步,线程执行到barrier时要停下等待,直到所有线程都执行到barrier时才继续往下执行。
example
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <time.h>
#include <string.h>
#include "omp.h"
#define N 1000
#define OMP_THREADS 4 // CPU OpenMP 线程数
int main(void) {
int LINE_FOR_CPU_THREADS = (N + OMP_THREADS - 1) / OMP_THREADS; // 定义每个CPU线程计算的行数
int A[N][N]; // 定义数组A
int i, j; // 随机初始化数组A,每行从下标1开始,第0个元素用于记录该行最大值
for (i = 0; i < N; i++){
A[i][0] = 0;
for (j = 1; j < N; j++){
A[i][j] = rand()%10; } }
#pragma omp parallel for num_threads(OMP_THREADS) // 启动多线程计算
for (i = 0; i < OMP_THREADS; i++) {
printf("ThreadIdx: %d\n", i);
int k, lineID, sum;
int line_for_cpu_idx = LINE_FOR_CPU_THREADS * i;// 计算该线程的起始计算行号
for (lineID = line_for_cpu_idx; lineID < line_for_cpu_idx + LINE_FOR_CPU_THREADS; lineID++) {
if (lineID >= 0 && lineID < N) {
sum = 0;
for (k = 1; k < N; k++) {
sum += A[lineID][k];
}
A[lineID][0] = sum; } } }
for (i = 0; i < N; i++) { // 回到主线程,输出计算结果
for (j = 0; j < N; j++)
printf("%d ", A[i][j]);
printf("\n"); }
}
CUDA
GPU
- 专门面对高并发的计算任务(核:小+多)
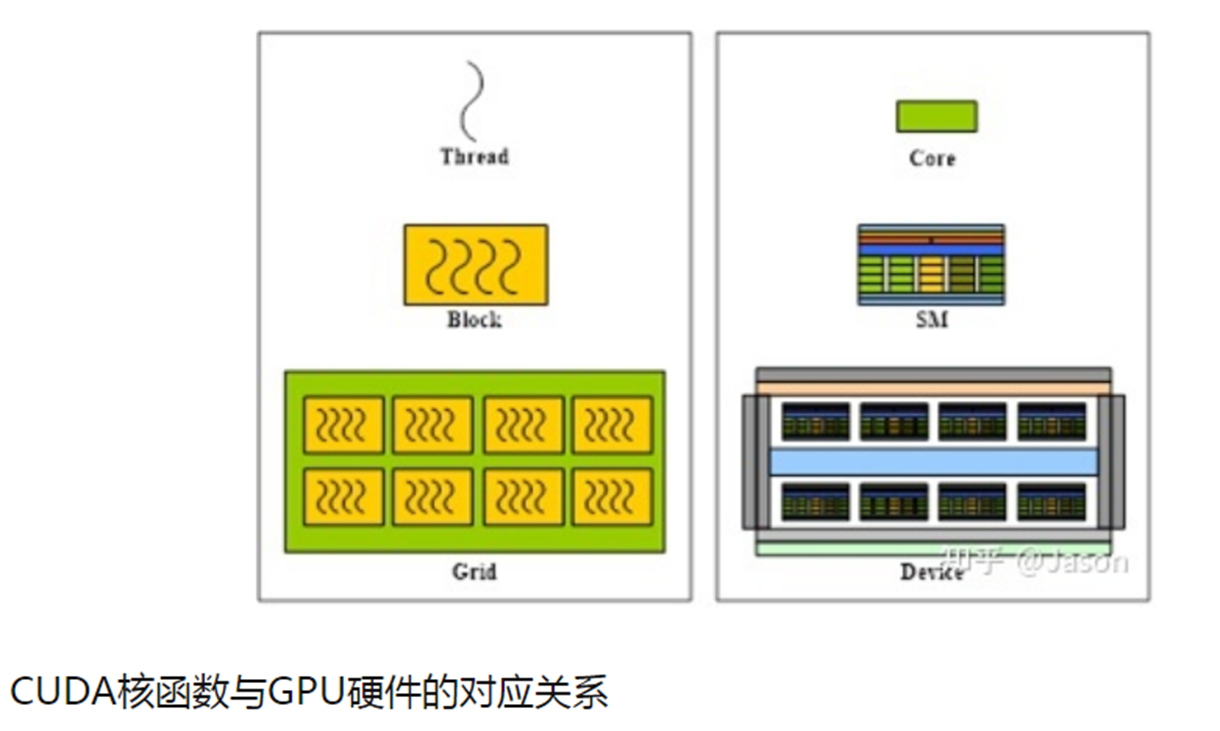
- 基本的运算单元被称为流处理器(SP)。
- 多个流处理器、寄存器、缓存和指令控制单元组成 流多处理器(SM)。
- SM是GPU执行指令的基本单位,在同一SM内的SP具有共享的高速一级缓存。整个GPU则是由多组SM、共享二级缓存以及显存控制器等组成。
CUDA编程
- CUDA编程基于SIMD编程模型。执行核函数之前,用户需要(手动)将数据通过PCI-E通道由内存复制到显存中;核函数执行完毕后,用户再将运算后的数据由显存复制回主机的内存中。
- GPU上执行的代码称为核函数(kernel)
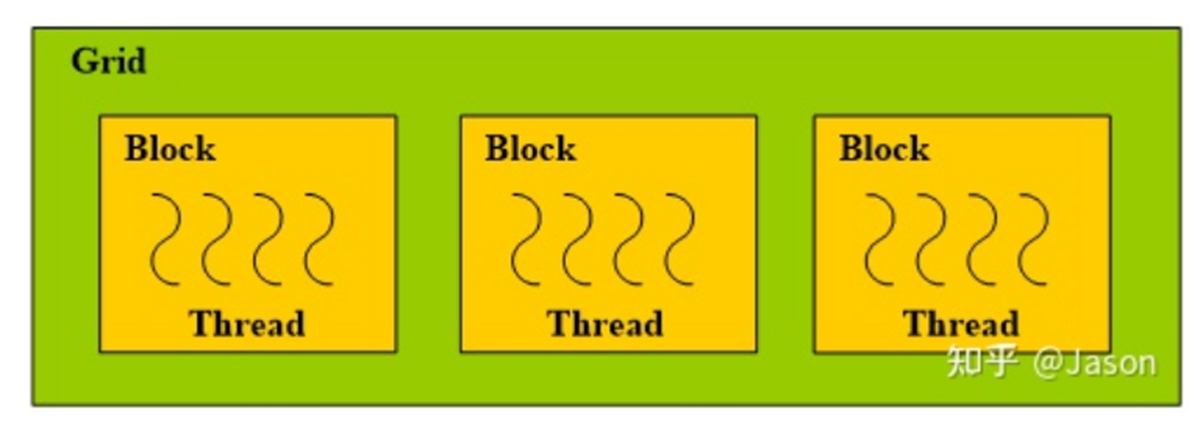
CUDA线程的组织:
线程(Thread):CUDA程序的基本执行单元。每个线程内的指令都会顺序执行。遵循SIMD编程模型,所有的线程都会执行相同的代码或相同代码的不同分支。理论上,所有的线程都是并行执行的,没有先后之分。
线程块(Block):由一组线程组成。每个线程块内部线程之间可以进行协作,有可以共同访问的共享内存。
CUDA程序执行时,每个线程块会在GPU上同一个SM中执行,每个线程块内的线程又会以线程束(Wrap)为单位,分组在SM中执行。线程束是GPU在执行时调度的最小单位。大小一般为32。
网格(Grid):一组线程块的集合。网格里的线程块会被调度到GPU的多个SM上去执行。线程块之间没有同步机制,执行的先后顺序不确定。
CUDA核函数
GPU端运行的代码,规定GPU的各个线程访问哪些数据执行什么计算
每个核函数对应一个Grid,一个Grid中有一个或多个block, 一个block中有一个或多个thread
kernel<<<Dg, Db, Ns, S>>>(param list)Dg:int型或者dim3类型(x,y,z),定义一个Grid中Block是如何组织的,如果是int型,则表示一维组织结构Db:int型或者dim3类型(x,y,z),定义一个Block中Thread是如何组织的,如果是int型,则表示一维组织结构Ns:size_t类型,可缺省,默认为0; 用于设置每个block除了静态分配的共享内存外,最多能动态分配的共享内存大小,单位为byte。 0表示不需要动态分配。S:cudaStream_t类型,可缺省,默认为0。 表示该核函数位于哪个流。1
2
3
4dim3 grid(3,2,1), block(4,3,1);
kernel_name<<<grid, block>>>(...);
//表示一个Grid中有3x2x1=6个Block,在(x,y,z)三个方向上的排布方式分别是3、2、1;
//一个Block中有4x3x1=12个Thread,在(x,y,z)三个方向上的排布方式分别是4、3、1。内置变量
blockIdx:索引到线程块
threadIdx:索引到某个块内的线程
blockDim:得到一个块内线程总数
gridDim:得到一个格内块总数
n在一维的情况下,计算线程全局id公式为
- 线程全局id = blockIdex.x * blockDim.x + threadIdx.x
n在一维的情况下,核函数内的线程总数为
- 核函数的线程总数 = gridDim.x * blockDim.x
三、存储系统
访问周期和命中率
\(\begin{aligned}&T=HT_1+(1-H)T_2\\&\text{当命中率}H\to1\text{时,}T\to T_1\end{aligned}\)
T1:M1存储器的访问周期
T2:M2存储器的访问周期
并行存储器
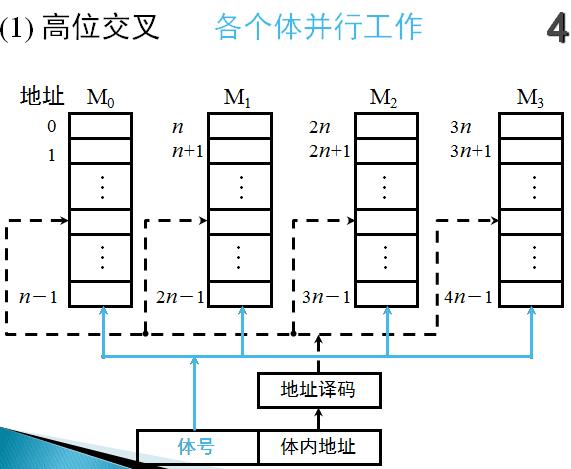
高位交叉
目的:扩大存储容量
实现方法:用地址码的高位部分区分存储体号
特点:
- 具备并行工作的条件:每个存储模块有各自独立的控制部件,包括地址寄存器、地址译码器等,可以独立工作
- 编址的连续性:由于程序的连续性和局部性,大部分情况下,指令序列和数据分布在同一个存储模块中。只有当指令序列跨越两个存储模块时,才能并行工作
- 扩大容量,未提高速度
低位交叉(多体交叉编址)
- 目的:提高存储器访问速度
- 实现方法:用地址码的低位部分区分存储体号
- 虽然多体并行主存系统和单体并行主存系统最大频宽可以相同,但多体地址可以灵活设置,只要是在不同分体中,就能得到比单体更高的频宽。因为程序常有转移出现,使得实际访问地址不一定均匀分布在交叉分体上,致使效率下降。统计表明,采用多体并行主存结构的计算机系统获得的实际频宽约是最大理想频宽的1/3。
- 特点:
- 存储体的访问周期Tm,由n个存储体构成的主存储器,各存储体的启动间隔 $t=T_m/n$
- 低位交叉存储器是一种采用分时工作工作的并行存储系统。在连续工作的情况下,保持每个存储体速度不变,则整个存储器速度可望提高n倍
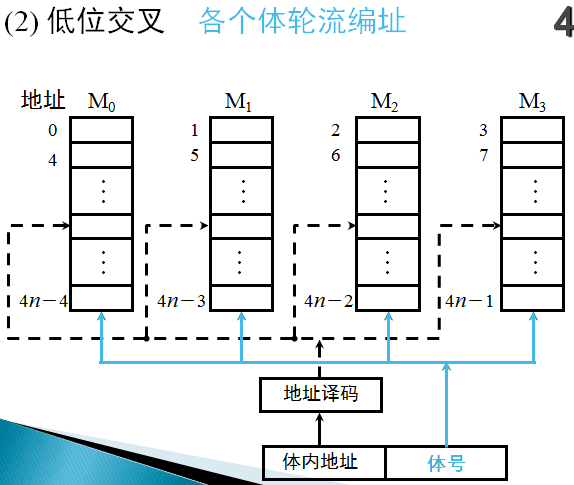
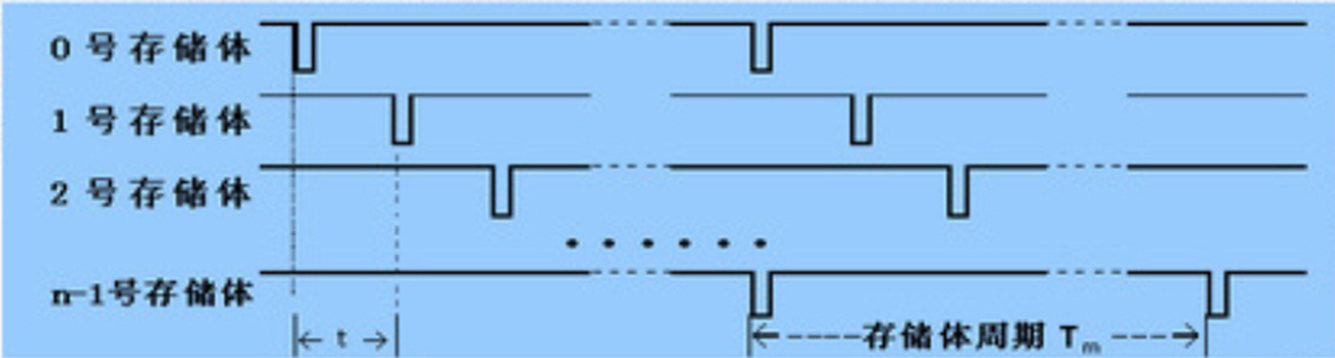
- 存储器的速度不随存储体个数的增加而线性提高,即n个存储体组成的存储器的加速比通常小于n。原因在于访问冲突:取指令时可能发生程序转移,取操作数时存在数据离散性
堆栈型替换算法
基本特点:
随着分配给程序的主存页面数增加,主存的命中率也提高,至少不下降
FIFO不是堆栈型算法,LRU,LFU,OPT是堆栈型
提高主存命中率方法
影响命中率的因素
- 页面替换算法
- 页面大小
- 页面大小为某个值时,命中率最大
- 随页面大小增大,主存页面数减少,页面替换更频繁
- 主存储器容量
- 命中率随主存容量的增加而单调上升,但是梯度逐渐变小
- 对于堆栈型:容量增大,页面数增加,命中率提高
- 非堆栈:不一定单调上升,但总趋势上升
Cache一致性问题
造成Cache与主存不一致的原因:
- CPU写Cache,但没有立即写主存
- IO处理机或IO设备写主存,但没有写Cache
Cache的更新算法
- 写直达法,WT(Write-through)
CPU的数据写入Cache时,同时也写入主存
- 写回法,WB (Write-Back)
CPU的数据只写入Cache,不写入主存,仅当替换时,才把修改过的Cache块写回主存
Cache块表中为每一块设置一个修改位,初值为0。当块中任何一个字被修改时,修改位被置为1。
Cache性能计算
- 平均存储器访问时间 = 命中时间 + 不命中率 * 不命中代价
- CPU时间 = IC * (CPI + 不命中率 * 存储器存取次数/指令数 * 不命中代价) * T
Cache命中率相关因素
Cache的命中率随它的容量的增加而提高
组相联映像方式的Cache中,Cache容量一定时,块的大小对命中率的影响非常敏感
块很小时,命中率H很低
随着块大小的增加,程序的空间局部性起作用,同一块中的数据的利用率提高,块命中率H提高
达到最大值以后,命中率H随块大小的增加反而减少。当块非常大时,程序的局部性减弱
Cache命中率与组数的关系
在组相联映像的Cache中:
随着组数的增加, Cache的命中率降低
当组数不太大时(512组以下),命中率降低得相当少
当组数超过一定数量时,命中率下降非常快
相联度(每组块数)不是越大,命中率越高
虚拟存储器的工作方式、特点
虚拟存储器是指“主存-辅存”层次,它能使该层次具有辅存容量、接近主存的等效速度和辅存的每位成本,使程序员可以按比主存大得多的虚拟存储空间编写程序(即按虚存空间编址)
Cache的主要作用是弥补主存和CPU之间的速度差距,因此它的管理部件是用硬件实现的,并对程序员透明。
但虚拟存储器的主要作用是弥补主存和辅存之间的容量差距,因此它的管理部件基本上靠软件,适当结合硬件来实现,对系统程序员也不是透明的。
四、流水线
先行控制
使分析和执行部件分别连续不断地运行,使部件空闲状态减至最低
采用技术:
缓冲技术
预处理技术
先行控制与重叠区别:分析和执行部件可同时处理两条不相邻指令
流水技术特点
- 可以划分为若干互有联系的子过程(功能段)。每个功能段由专用功能部件实现。
- 实现功能段所需的时间应尽可能相等,避免因不等产生处理瓶颈,造成“断流”。
- 形成流水线处理,需要一段准备时间,称为“通过时间”。只有在此之后流水过程才能稳定。
- 指令流不能顺序执行时,会使流水过程中断;再形成流水过程,则需经过一段时间。不应经常“断流”,否则效率不高。
- 流水线技术适用于大量重复的程序过程,只有输入端能连续提供服务,流水线效率才能够得到充分发挥。
流水线时空图
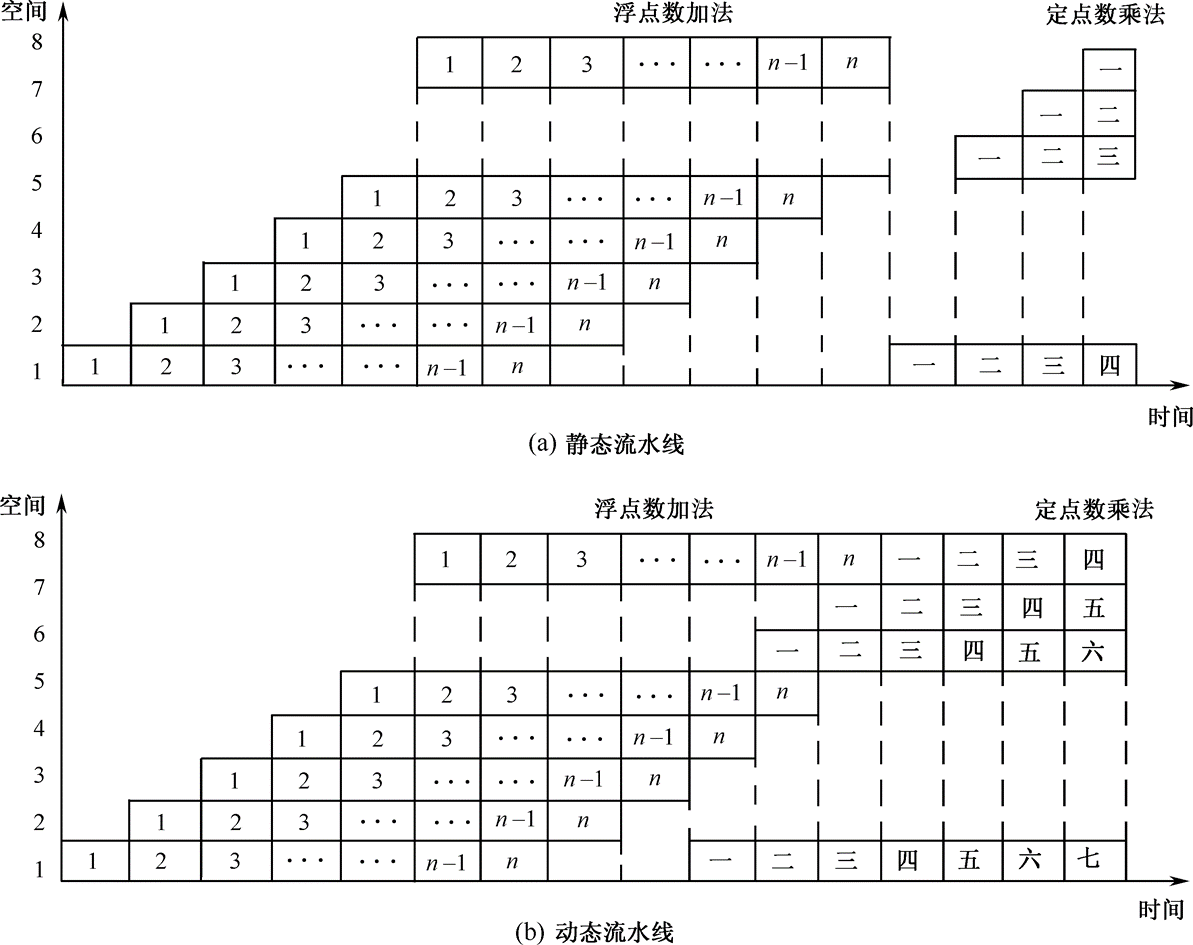
流水线性能指标

1. 吞吐率
单位时间内流水线能够处理的任务数
\(\mathrm{TP}=\frac{n}{T}=\frac{n}{m\times\Delta t_{0}+(n-1)\times\Delta t_{0}}=\frac{1}{\Delta t_{0}\times\left(1+\frac{m-1}{n}\right)}=\frac{\mathrm{TP}_{\max}}{1+\frac{m-1}{n}}\)
若各段时间不相等:
- \(\mathrm{TP}=\frac n{\sum_{i=1}^m\Delta t_i+(n-1)\Delta t_j}\), tj为最长的一段时间
2. 加速比
m段流水线的速度与等效的非流水线的速度之比称为加速比
\(S=\frac{T_\text{非流水}}{T_\text{流水}}=\frac{mn\Delta t_0}{m\Delta t_0+(n-1)\Delta t_0}=\frac{mn}{m+n-1}=\frac m{1+\frac{m-1}n}\)
若各段时间不相等:
- \(S=\frac{n\sum_{i=1}^m\Delta t_i}{\sum_{i=1}^m\Delta t_i+(n-1)\Delta t_j}\)
3. 效率
工作时间的时空区与流水线中各段总的时空区之比
\(E=\frac{nm\Delta t}{m(m+n-1)\Delta t}=\frac n{m+n-1}=\frac{S_p}m=T_p\Delta t\)
若各段时间不相等:
\(E=\frac{n\sum_{i=1}^m\Delta t_i}{m\biggl[\sum_{i=1}^m\Delta t_i+(n-1)\Delta t_j\biggr]}=\frac{n\text{ 个任务占用的时空区}}{m\text{ 个段总的时空区}}\)
非线性流水线调度
因功能段使用冲突,调度相对复杂
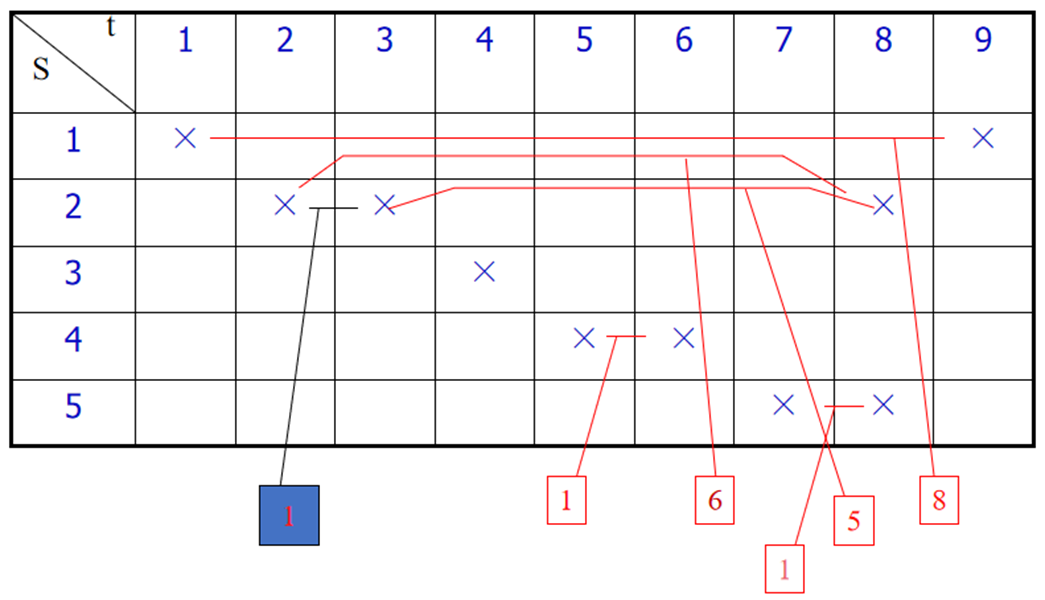
预约表
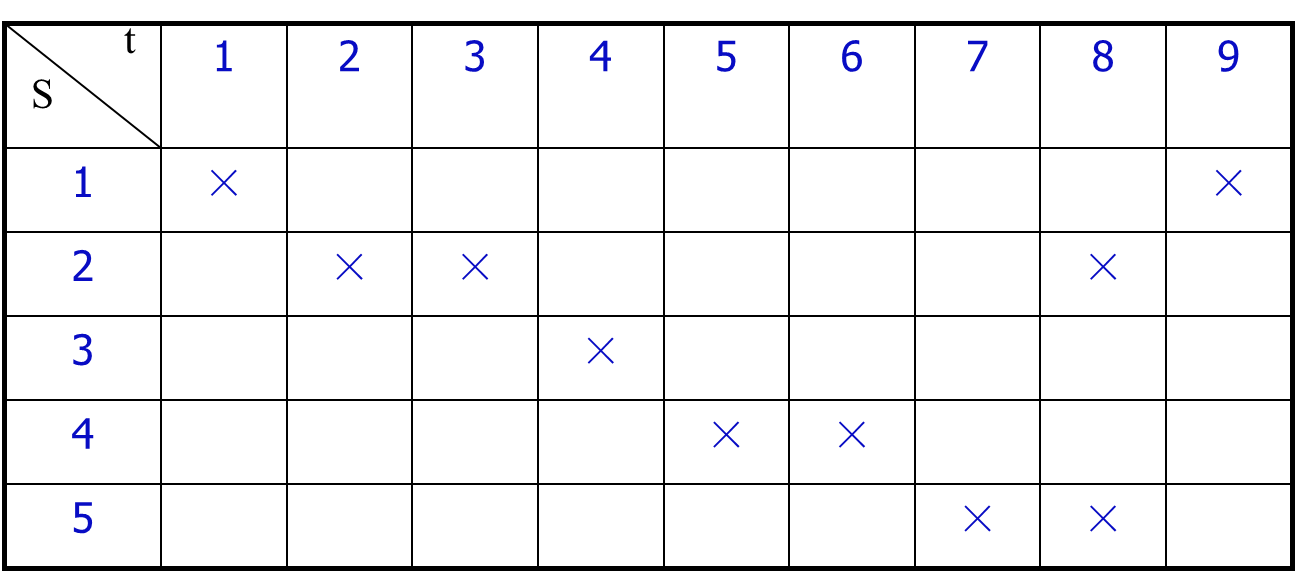
禁止向量
F=(8,6,5,1)

冲突向量
C0 =(10110001)
状态转换图
C0每过一拍逻辑右移一位,若移出0,则允许后续指令进入流水线,再与C0按位“或”,形成新的冲突向量Ci;(根据禁止表F的允许等待时间,本例:2,3,4,7,就是C0中0的位置)
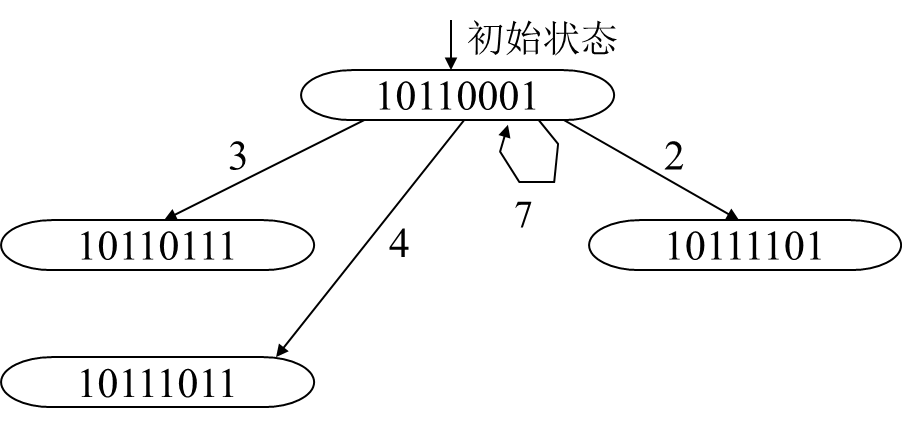
冲突向量C0经过移位后和后续指令(该指令仍然具备冲突向量C0特征)求或,得出新的冲突向量Ci
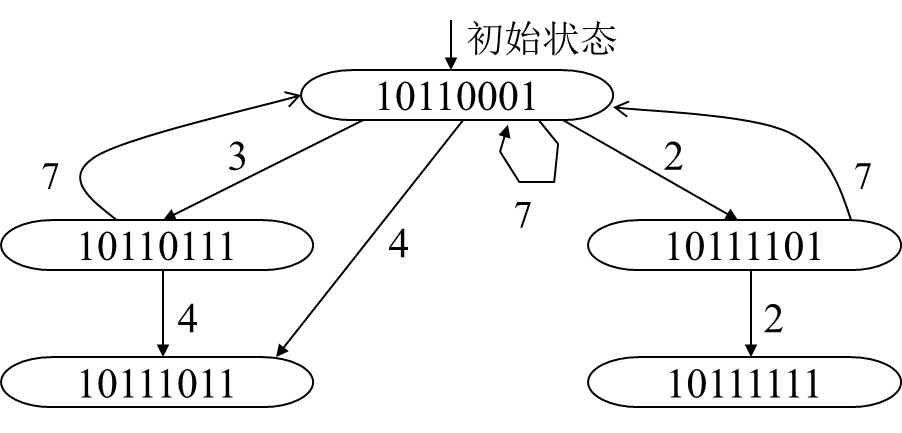
重复上一步骤,直到不再生成新的冲突向量为止。(特例:如果有个状态是全1,11111111。则需要隔9隔周期,即所有状态前加0,按011111111处理)
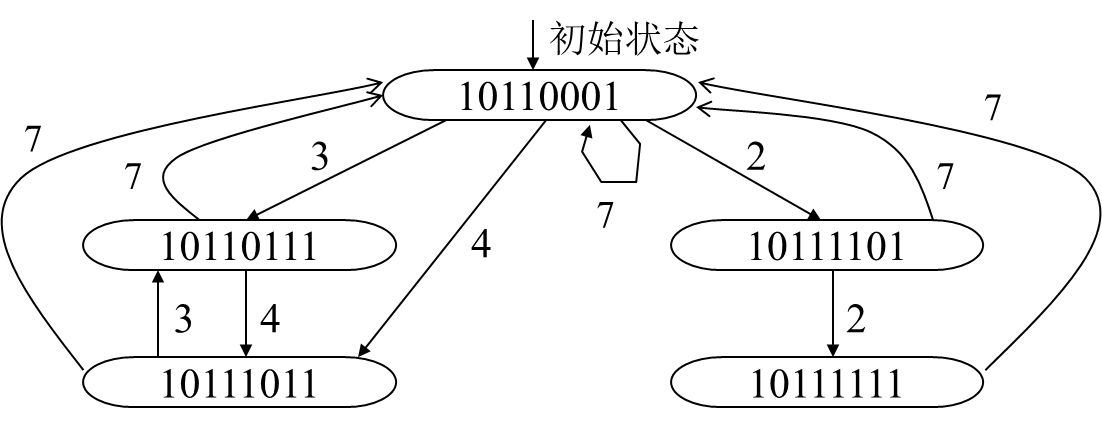
找出迫切循环
简单循环—每个状态只出现一次的等待时间循环。
迫切循环是指从各自初始状态输出的边缘都具有最小等待时间的简单循环,即平均等待时间比其他等待时间更小。
平均间隔拍数,也称为平均启动距离

超标量/超流水
| 机器类型 | k段流水线基准标量处理机 | m度超标量处理机 | n度超流水线处理机 | (m, n)度超标量超流水线处理机 |
|---|---|---|---|---|
| 机器流水线周期 | 1个时钟周期 | 1 | 1/n | 1/n |
| 同时发射指令条数 | 1条 | m | 1 | m |
| 指令发射等待时间 | 1个时钟周期 | 1 | 1/n | 1/n |
| 指令级并行度(ILP) | 1 | m | n | m×n |
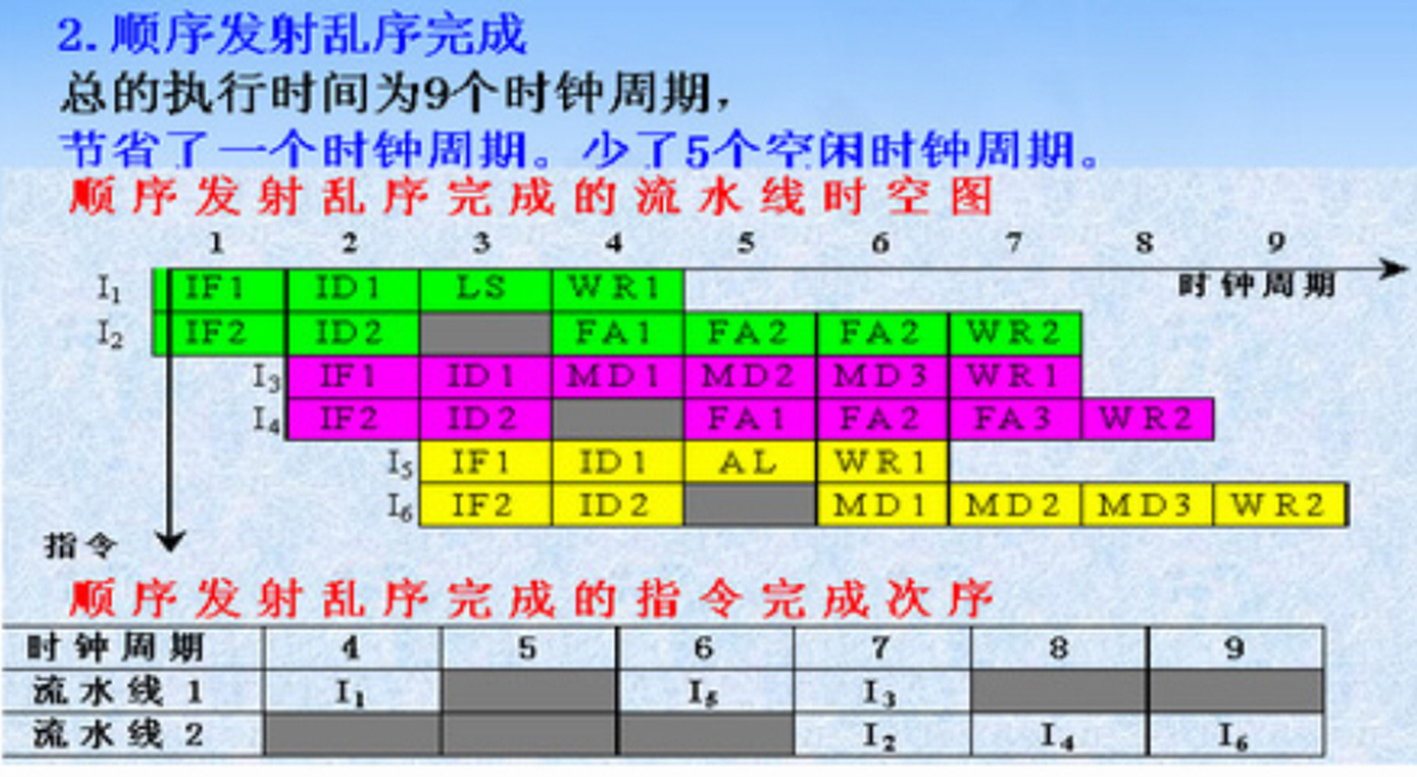
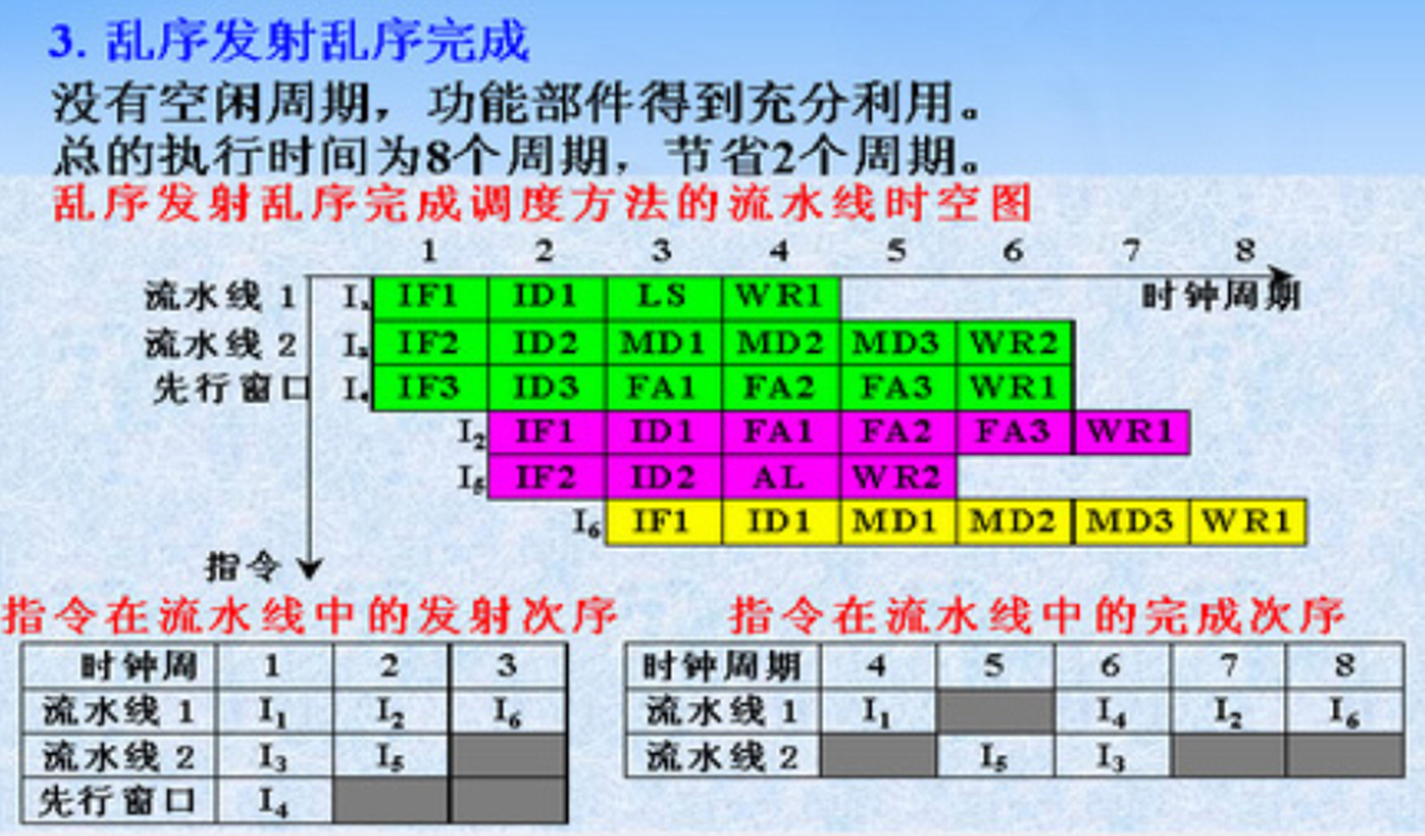
多流水线调度
顺序发射,资源相关


五、并行处理机
并行性概念
在同一时刻或同一时间间隔内完成两种或两种以上的性质相同或不同的工作,只要在时间上相互重叠,均存在并行性。
同时性:两个或多个事件在同一时刻发生的并行性
并发性:两个或多个事件在同一时间间隔内发生的并行性
并行性等级
从执行角度
指令内部并行:指令内部的微操作之间的并行
指令间并行:并行执行两条或多条指令
任务级或过程级并行:并行执行两个或多个过程或任务(程序段)
作业或程序级并行:在多个作业或程序间的并行
从数据处理角度
- 字串位串:同时只对一个字的一位进行处理,不存在并行性
- 字串位并:同时对一个字的所有位进行处理,
- 字并位串:同时对多个字的同一位进行处理
- 字并位并:同时对多个字的所有位或部分位进行同时处理
提高并行性的三条途径
时间重叠
流水线
多个处理过程在时间上相互错开,轮流重叠使用同一套硬件的各个部件,以加快部件的周转而提高速度。时间重叠原则上不要求重复的硬件设备
资源重复
- 重复设置多个硬件部件以提高计算机系统的性能
资源共享
- 分时系统、分布式系统。利用软件方法,使多个用户分时使用同一个计算机系统。
并行处理机(SIMD)定义
多个处理部件按照一定方式互联,在同一个控制部件控制下,对各自的数据完成同一条指令规定的操作
单级互连函数
交换互联网络(立方体单级网络)Cube
出端编码与连接的入端结点的编码有一位相反
\(\mathrm{Cube_0=(b_2b_1b_0)~;~Cube_1=(b_2\overline{b_1}b_0)~;}\)
全混洗网络 Perfect Shuffle
把二进制结点号循环左移一位
\(S(x_{n-1}x_{n-2}\cdots x_1x_0)=x_{n-2}x_{n-3}\cdots x_1x_0x_{n-1}\)
子混洗S(k),最低k位循环左移一位
\(S_{\mathrm{(k)}}(\mathrm{x_{n-1}x_{n-2}\cdots x_{k}x_{k-1}x_{k-2}\cdots x_{1}x_{0}})=\mathrm{x_{n-1}x_{n-2}\cdots x_{k}x_{k-2}\cdots x_{1}x_{0}x_{k-1}}\)
超混洗S(k),最高k位循环左移一位
\(S^{(\mathrm{k})}(\mathrm{X_{n-1}X_{n-2}\cdots X_{n-k}X_{n-k-1}\cdots X_1X_0})=\mathrm{X_{n-2}\cdots X_{n-k}X_{n-1}X_{n-k-1}\cdots X_1X_0}\)
逆混洗S-1,右移一位
\(S^{-1}(x_{n-1}x_{n-2}\cdots x_1x_0)=x_0x_{n-1}x_{n-2}\cdots x_1\)
移数函数 PM2I
输入端向量循环移动一定的位置
\(\begin{aligned}&\mathrm{PM2I_{+i}(j)=(j+2^i)~mod~N;}\\&\mathrm{n=log_2N,0\leq i\leq n-1,}\\&\mathrm{PM2I_{-i}(j)=(j-2^i)~mod~N;\quad0\leq j\leq N-1}\end{aligned}\)
蝶式函数 Butterfly
最高位和最低位互换位置
\(B(x_{n-1}x_{n-2}\cdots x_1x_0)=x_0x_{n-2}\cdots x_1x_{n-1}\)
反位序 Bit Reversal
将二进制自变量的位序反过来
\(R(x_{n-1}x_{n-2}\cdots x_1x_0)=x_0x_1\cdots x_{n-2}x_{n-1}\)
多级互连网络
多级立方体网络STARAN
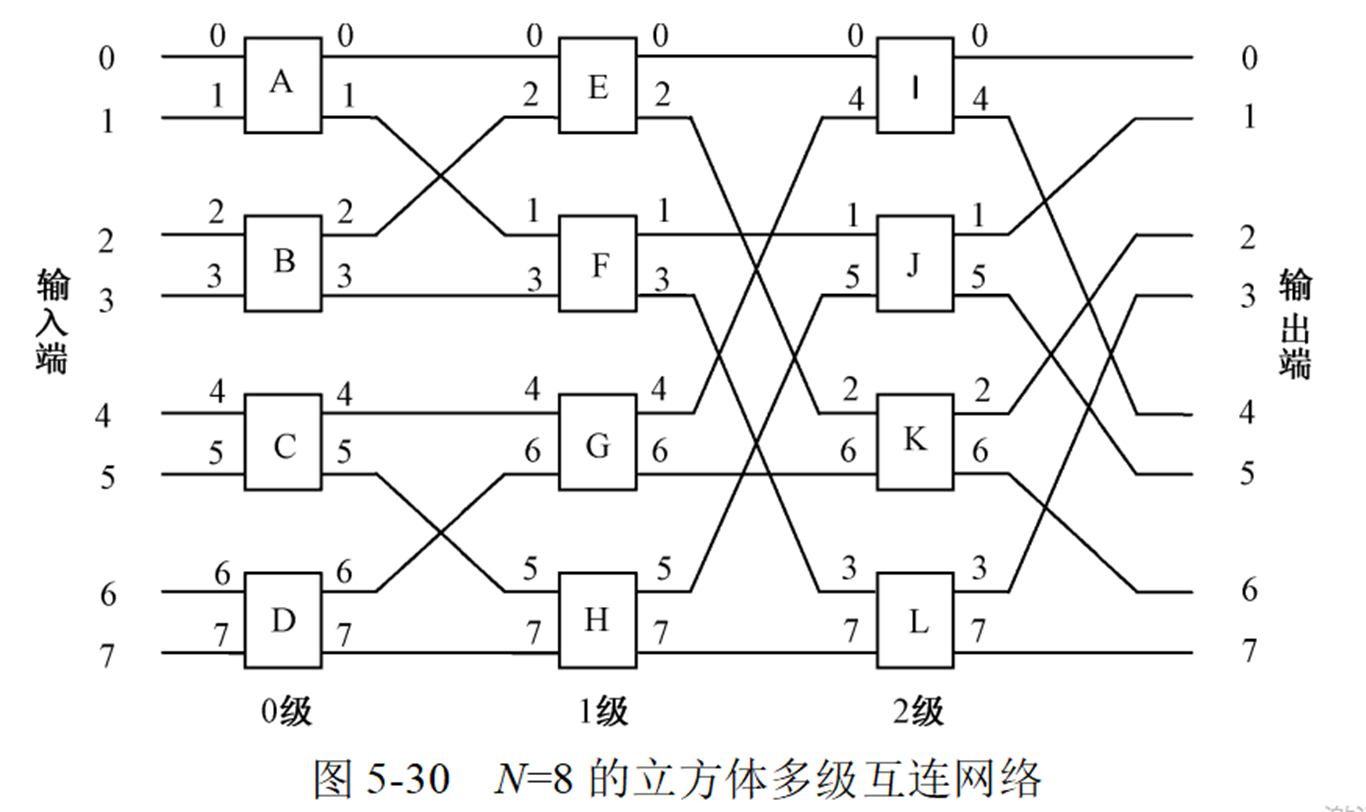
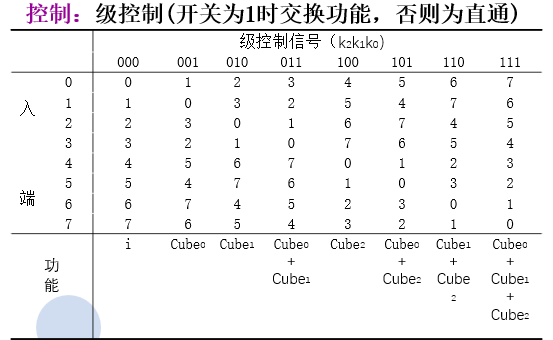
多级混洗交换网络(Omega网络)
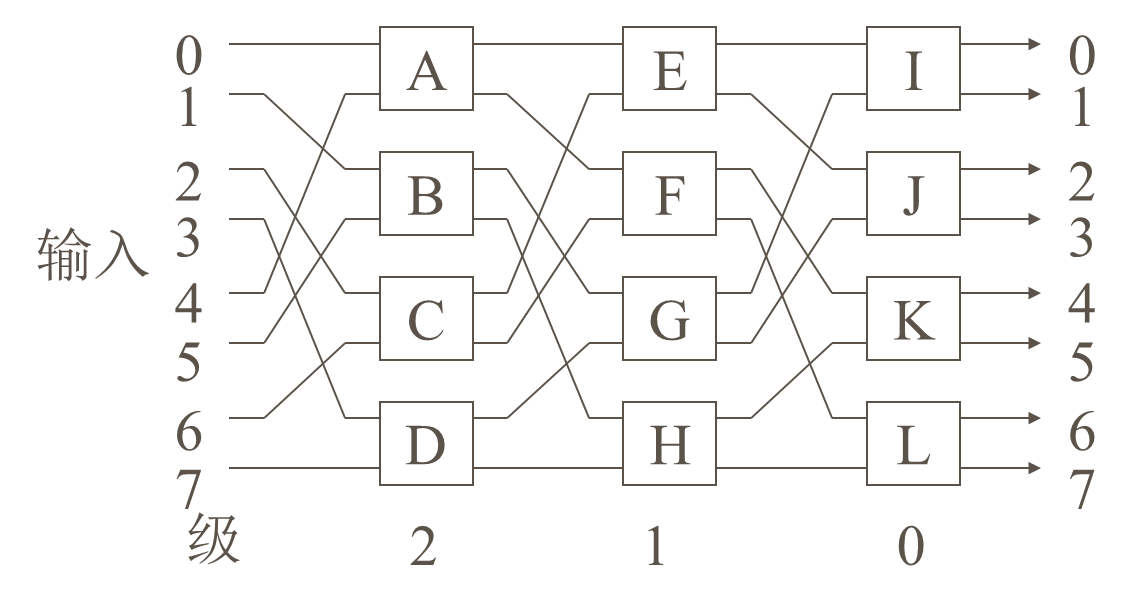
多处理机(MIMD)定义
- 包含两个或两个以上功能大致相同的处理器;
- 所有处理器共享一个公共内存;
- 所有处理器共享I/O通道、控制器和外围设备;
- 整个系统由统一的操作系统控制,在处理器和程序之间实现作业、任务、程序段、数组和数组元素等各级的全面并行。
互连网络
无阻塞交叉开关
当不断增加总线数目时,使得每个存储器模块都有它自己单独可用的通路。由于每个存储器模块有其自己的总线,所以交叉开关实现了存储器模块的全连接。
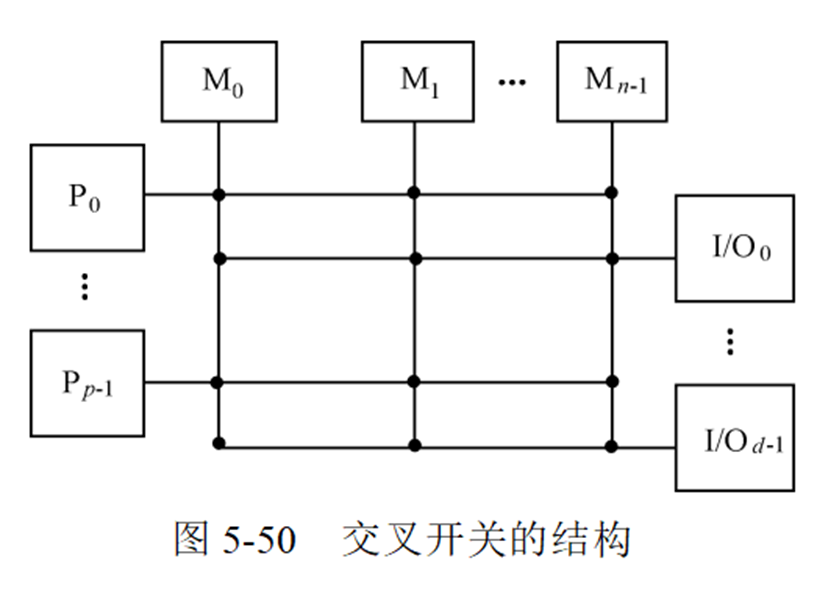
多端口存储器
把分布在交叉开关矩阵网络上的控制、转接、优先级仲裁等逻辑功能转移到存储器模块的接口上,就形成了多端口存储器系统。
多端口存储器可不使用互联网络

多处理机系统的cache校验
静态一致性校验
基本思想是:只让该进程的独用信息(指令和操作数据)和共享只读信息进入本处理机的cache,而不准共享可写(即可修改)信息进入cache,让其只留在主存中。
动态一致性校验
基本思想是,在若干cache中使同一个信息(指令、数据)始终保持动态一致。
•广播法
•目录法
并行编译
有下列表达式: Z=E+A*B*C/D+F
利用普通串行编译算法,产生三元指令组为
1 *AB
2 *1C
3 /2D
4 +3E
5 +4F
6 =5Z
指令间均相关,需5级运算。
如采用并行编译算法可得:
1 *AB 2 /CD
3 *12 4 +EF
5 +34
6 =5Z
1、2为第一级;3、4为第二级;5、6为第三级;
分配给两个处理机,只需三级运算。
六、集群、网格、云计算
集群计算机分类
- 高可用性(High Availability)集群:致力于提供高度可靠的服务
- 负载均衡(Load Balance)集群:使任务在集群中尽可能平均地分摊到不同的计算节点处理,提高对任务的处理效率
- 高性能计算(High Performance Computing)集群:把一个问题的计算任务分配到多个计算节点上,利用这些计算节点的资源来完成任务,从而完成单机不能胜任的工作
MPI并行编程
最基本的MPI函数:
(1) MPI_Init(); 初始化MPI环境
(2) MPI_Comm_size(); 获取进程数量
(3) MPI_Comm_rank(); 获取本进程进程号
- MPI_Finalize(); 退出MPI环境
(5) MPI_Send(); 点对点发送信息
(6) MPI_Recv(); 点对点接收信息
MPI_Bcast(); 广播
MPI_Reduce(); 规约
MPI_Gather(); 收集
MPI_Scatter(); 散发
MPI_Barrier(); 同步
云计算特点
- 超大规模和廉价性
- 虚拟化
- 高可靠性
- 通用性
- 高可扩展性(弹性)
- 按需服务
简答
CISC & RISC
复杂指令系统CISC
- 提供复杂指令来提高性能
- 所含指令至少300条,甚至超过500条
- 设计目的:用最少的机器语言指令来完成所需的计算任务
- 使得硬件越来越复杂,造价相应提高,复杂的指令系统不但不容易实现,还可能降低性能
精简指令系统RISC
只保留使用频率很高的少量指令
其他复杂功能通过组合指令(子程序)实现
提供一些必要的指令以支持OS和高级语言
寻址方式不够灵活
CUDA
- CUDA编程基于SIMD编程模型。执行核函数之前,用户需要(手动)将数据通过PCI-E通道由内存复制到显存中;核函数执行完毕后,用户再将运算后的数据由显存复制回主机的内存中。
- GPU上执行的代码称为核函数(kernel)
CUDA线程的组织:
线程(Thread):CUDA程序的基本执行单元。每个线程内的指令都会顺序执行。遵循SIMD编程模型,所有的线程都会执行相同的代码或相同代码的不同分支。理论上,所有的线程都是并行执行的,没有先后之分。
线程块(Block):由一组线程组成。每个线程块内部线程之间可以进行协作,有可以共同访问的共享内存。
CUDA程序执行时,每个线程块会在GPU上同一个SM中执行,每个线程块内的线程又会以线程束(Wrap)为单位,分组在SM中执行。线程束是GPU在执行时调度的最小单位。大小一般为32。
网格(Grid):一组线程块的集合。网格里的线程块会被调度到GPU的多个SM上去执行。线程块之间没有同步机制,执行的先后顺序不确定。
并行处理机
多个处理部件按照一定方式互联,在同一个控制部件控制下,对各自的数据完成同一条指令规定的操作。
在单机系统里主要是采用时间重叠技术。把一件工作按功能分割为若干相互联系的部分,把每一部分指定给专门的部件完成,然后按时间重叠原则把各部分执行过程在时间上重叠起来,使所有部件依次分工完成一组同样的工作。
并行处理机主要是通过资源重复技术来实现并行处理的。它属于单指令流多数据流(SIMD)计算机一类。
从控制部件角度看,指令是串行执行的
从处理部件角度看,数据是并行处理的
提高并行性的三条途径
时间重叠
流水线
多个处理过程在时间上相互错开,轮流重叠使用同一套硬件的各个部件,以加快部件的周转而提高速度。时间重叠原则上不要求重复的硬件设备
资源重复
- 重复设置多个硬件部件以提高计算机系统的性能
资源共享
- 分时系统、分布式系统。利用软件方法,使多个用户分时使用同一个计算机系统。
并行性等级
从执行角度
指令内部并行:指令内部的微操作之间的并行
指令间并行:并行执行两条或多条指令
任务级或过程级并行:并行执行两个或多个过程或任务(程序段)
作业或程序级并行:在多个作业或程序间的并行
从数据处理角度
字串位串:同时只对一个字的一位进行处理,不存在并行性
字串位并:同时对一个字的所有位进行处理,
字并位串:同时对多个字的同一位进行处理
字并位并:同时对多个字的所有位或部分位进行同时处理
MPI
集群计算机分类
高可用性(High Availability)集群:致力于提供高度可靠的服务
负载均衡(Load Balance)集群:使任务在集群中尽可能平均地分摊到不同的计算节点处理,提高对任务的处理效率
高性能计算(High Performance Computing)集群:把一个问题的计算任务分配到多个计算节点上,利用这些计算节点的资源来完成任务,从而完成单机不能胜任的工作
最基本的MPI函数:
(1) MPI_Init(); 初始化MPI环境
(2) MPI_Comm_size(); 获取进程数量
(3) MPI_Comm_rank(); 获取本进程进程号
- MPI_Finalize(); 退出MPI环境
(5) MPI_Send(); 点对点发送信息
(6) MPI_Recv(); 点对点接收信息
虚拟存储系统
虚拟存储器是指“主存-辅存”层次,它能使该层次具有辅存容量、接近主存的等效速度和辅存的每位成本,使程序员可以按比主存大得多的虚拟存储空间编写程序(即按虚存空间编址)
Cache的主要作用是弥补主存和CPU之间的速度差距,因此它的管理部件是用硬件实现的,并对程序员透明。
但虚拟存储器的主要作用是弥补主存和辅存之间的容量差距,因此它的管理部件基本上靠软件,适当结合硬件来实现,对系统程序员也不是透明的。
流水技术特点
- 可以划分为若干互有联系的子过程(功能段)。每个功能段由专用功能部件实现。
- 实现功能段所需的时间应尽可能相等,避免因不等产生处理瓶颈,造成“断流”。
- 形成流水线处理,需要一段准备时间,称为“通过时间”。只有在此之后流水过程才能稳定。
- 指令流不能顺序执行时,会使流水过程中断;再形成流水过程,则需经过一段时间。不应经常“断流”,否则效率不高。
- 流水线技术适用于大量重复的程序过程,只有输入端能连续提供服务,流水线效率才能够得到充分发挥。
8.并行存储器
高位交叉
目的:扩大存储容量
实现方法:用地址码的高位部分区分存储体号
特点:
具备并行工作的条件:每个存储模块有各自独立的控制部件,包括地址寄存器、地址译码器等,可以独立工作
编址的连续性:由于程序的连续性和局部性,大部分情况下,指令序列和数据分布在同一个存储模块中。只有当指令序列跨越两个存储模块时,才能并行工作
扩大容量,未提高速度
低位交叉(多体交叉编址)
- 目的:提高存储器访问速度
- 实现方法:用地址码的低位部分区分存储体号
- 虽然多体并行主存系统和单体并行主存系统最大频宽可以相同,但多体地址可以灵活设置,只要是在不同分体中,就能得到比单体更高的频宽。因为程序常有转移出现,使得实际访问地址不一定均匀分布在交叉分体上,致使效率下降。统计表明,采用多体并行主存结构的计算机系统获得的实际频宽约是最大理想频宽的1/3。
- 特点:
- 存储体的访问周期Tm,由n个存储体构成的主存储器,各存储体的启动间隔 $t=T_m/n$
- 低位交叉存储器是一种采用分时工作工作的并行存储系统。在连续工作的情况下,保持每个存储体速度不变,则整个存储器速度可望提高n倍